What is League of Legends Churn Predictor?
New League of Legends (LoL) players begin as a level 1 "summoner". They must play enough matches against computers to become a level 3 summoner (roughly 3-4 matches) before they can play against other humans. League of Legends matches are often 15-30 minutes each, making the investment to become a level 3 summoner significant for a new player.
Given gameplay data from the first match of a new League of Legends player, this project seeks to predict whether that player will get to level 3 within one month of their first match.
Background motivation
Churn rate is often defined as the number of customers/players/users that have stopped using a product/service for a specific period of time (perhaps a month). Generally, churn rate considers the entire customer base (not just new or old customers). However, for a product like a video game, the first few moments have a profound can cause someone to never play the game again or it can plant the seed of a superfan that has great loyalty and interest in everything about the game.
There are some acceptable reasons why a customer would leave a product/service, perhaps the customer has happily fulfilled their needs with the product and it was a natural time for them to stop using the product. However, many other reasons might be avoidable, for example, in a game like League of Legends, a player may stop playing the game due to frustration with non-intuitive controls or game mechanics. Maybe even just a small encouragement could completely change that player's outlook on those first few experiences with the game.
With that in mind, this churn predictor project seeks to identify these players that may give up on the game before giving it a proper chance to impress them.
Data Collection
This project gathers data from Riot's API [1] using the Cassiopeia [2] python library.
The API gives access to basic data about a player as well as their match history and in-game data from each match. Note, the API spans three years from the current date, so any data older than three years is not accessible.
Here is an example of some basic information you can get from a player:
| Summoner name | Summoner id | Summoner level | Region (server location) | Number of matches (in the last three years) |
|---|---|---|---|---|
| Msendak | 37709821 | 52 | North America | 2806 |
Here are some data points from this player's most recent match:
| Match creation (date and time) |
Match duration (hh:mm:ss) |
Match type | Game Statistics | Win | Role | Kills | Deaths | Assists |
|---|---|---|---|---|---|---|---|---|
| 05/02/2018 20:44:28 |
00:16:48 | Draft Unranked 5x5 | No | Support | 4 | 2 | 0 | |
These are just a few statistics, in total we have over 100 data points for each new player's first match.
The big challenge
There is just one complication in getting this data: you need a player's name or id in order to get their match data. The API does not provide any way to obtain random player names. The only player names you can obtain are those in the Challenger and Master leagues (the highest ranking competitive players... the dead opposite of new players).
But there's hope! The API tells you the names of other players that were in a given game. Most commonly a game has 10 players (or 5 for new players: 5 humans vs. 5 computers). So if I know one player that played 10 games, that's theoretically 90 new players I have access to (if that one player never played with the same players twice).
Because Riot's matchmaking system tends to place people of similar levels in the same game, I created a new account and played my first match on that account. This gave me four other low level players to potentially add to my dataset. I then looked at their match histories to find low level players that they played with.
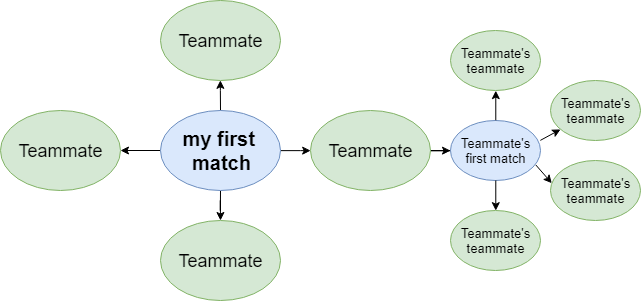
I continued this iterative, branching process until I finally had a dataset of over 1,000 players and the stats from each of those player's first match.
Exploratory Data Analysis
There are over 100 features we could examine in this dataset, but since we've gathered this data primarily to model a prediction task, we will limit our exploratory analysis to features that feel most relevant to that task.
First let's see when the players in my dataset played their first match.
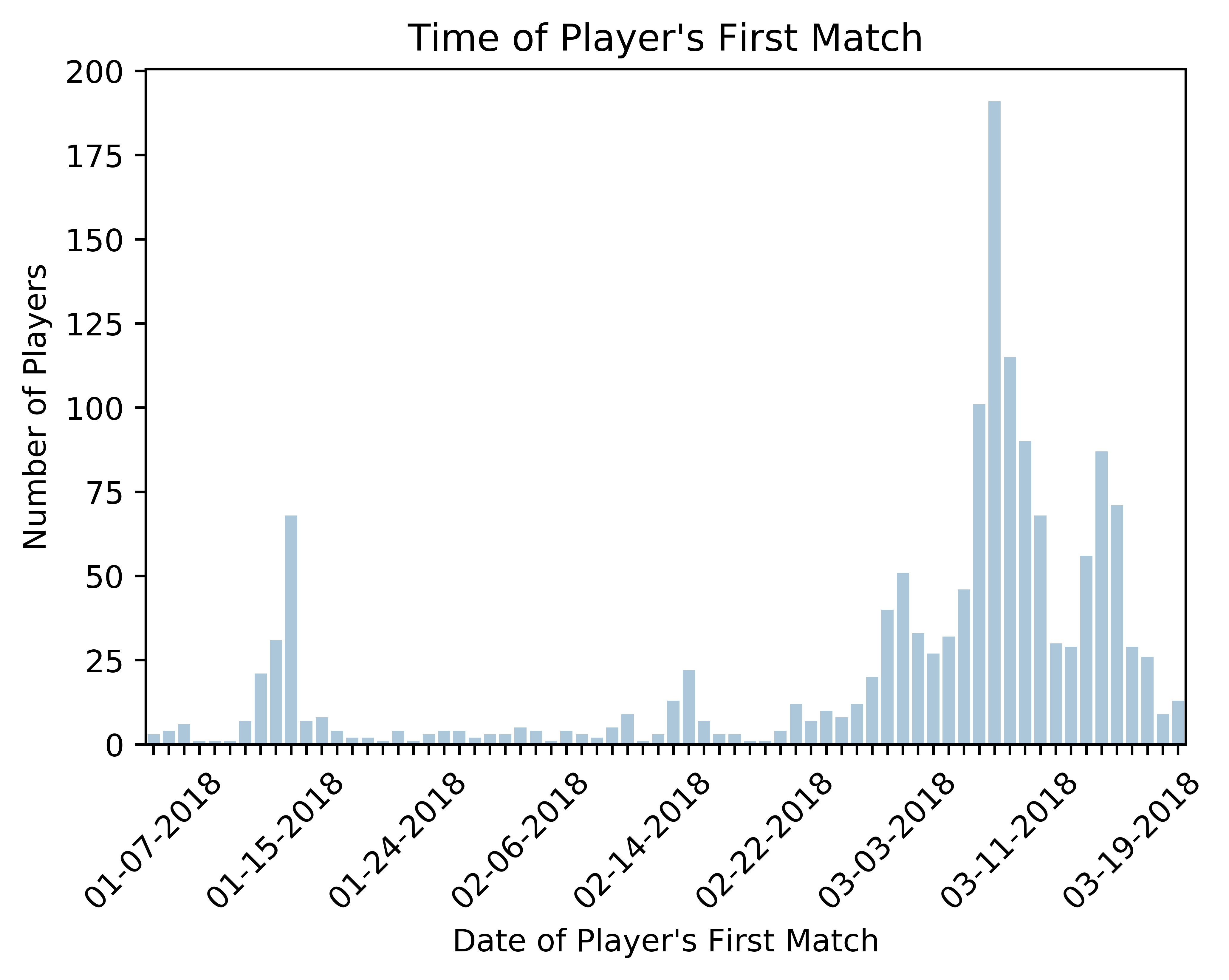
As you can see, all players began playing in 2018 and most in early to mid May. This is due to the constraints I made when collecting the data, but seeing this, it may be worth trimming off players that began playing before May as this could add noise or overfitting for our model. However I am choosing to leave these players in the dataset.
Because the prediction task I want to model later revolves around a player's "summoner level" let's take a look at that.
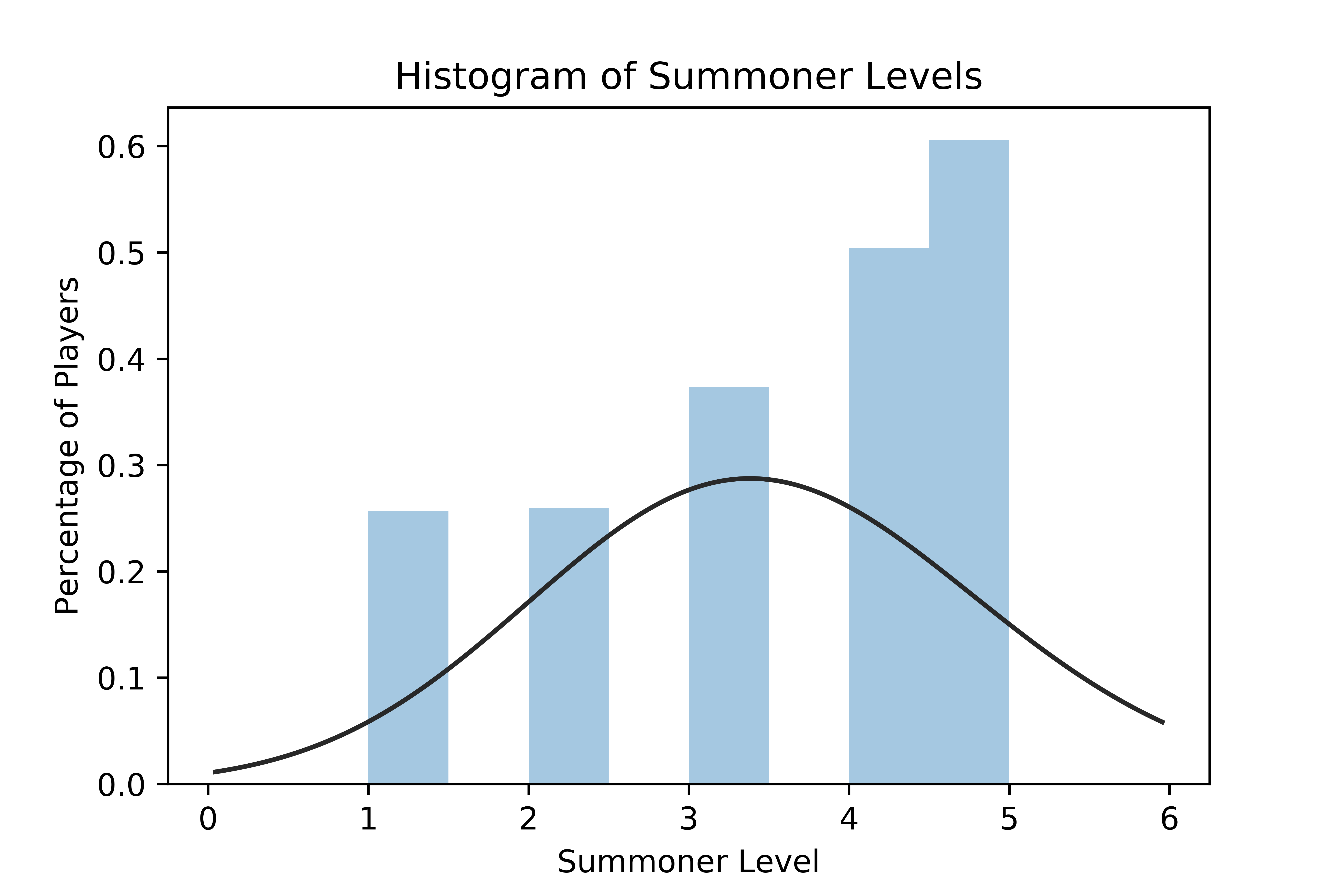
Notice how the distribution is skewed toward players that are levels four and five. This is another artifact of the way data was collected and does not necessarily mean that more LoL players are levels four and five than one through three.
Next let's apply prinicpal component analysis to our data to get a better idea of which features have the most explanatory power.
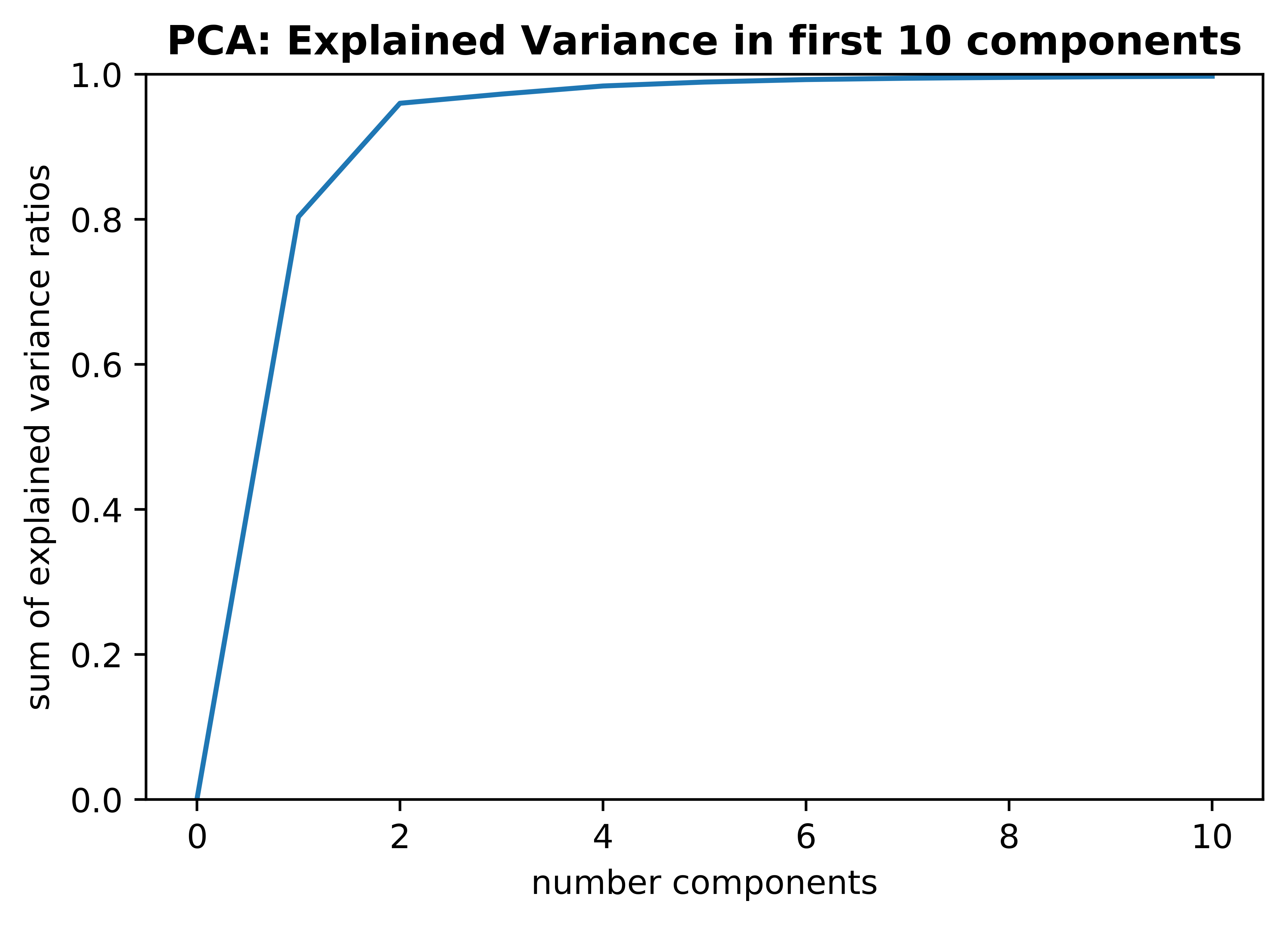
You can see how the majority of variance in the data can be explained in the first two components (95.75% to be exact).
Let's see what features are most important to those components.
| Top Features | First PCA component | Second PCA component |
|---|---|---|
| Total Damage Dealt | 74.92% | 24.15% |
| Physical Damage Dealt | 55.37% | 56.52% |
| Magic Damage Dealt | 16.26% | 72.91% |
As you can see, all features with high variance are thematically linked to the idea of "dealing damage".
Now that we have some idea of how the dataset looks in general, with the help of the principal component analysis and my intuition, I'll handpick a few features that I think will be important in differentiating players that give up on LoL before reaching level 3.
| New players that finished tutorial matches (n = 1109) |
New players that didn't finish tutorial matches (n = 386) |
Significantly different? (p-value) |
|
|---|---|---|---|
| Win rate | 95.67% | 96.89% | NO (0.29) |
| KDA (kills, deaths, assists) |
8.49 | 6.00 | YES (0.00001) |
| Average match duration (hh:mm:ss) |
00:19:18 | 00:18:26 | YES (0.00821) |
| Average gold earned | 7983 | 6728 | YES (2.59 x 10 ^ -11) |
| Average minions killed | 30 | 49 | YES (6.61 x 10 ^ -14) |
| Average damage dealt | 28614 | 46486 | YES (6.39 x 10 ^ -12) |
Note: p-values were obtained from two-tailed t-tests (without correction and alpha=0.05).
The first thing to notice is that whether you're a player that quickly abandoned the game or not, you probably won your first match against computers. This is almost certainly the intention of Riot, as they probably don't want the first experience you have with the game to be a giant red DEFEATED banner across your screen.
Next notice that while there is a small difference in KDA, but it's surprisingly underwhelming since you'd think players that were catching onto the game more quickly would be getting more kills and dying less.
However, when you look at the average gold earned by a player we see a striking difference. This makes sense since players that are getting the hang of the game faster are likely doing more actions that earn gold (killing champions, killing minions, killing turrets, etc.). Another big difference is seen in total damage dealt. This makes intuitive sense for the same reason as gold earned, and it was somewhat expected since it was seen to be so important to our PCA model earlier.
Lastly, looking at average number of minions killed by each group of players we see another huge difference. Anecdotally, being a relatively new player myself, it took several matches for me to start to appreciate just how important getting the last hit on minions (CS) is on your success in the game.
Let's plot the average minions kills by group to get a better sense of the difference there:
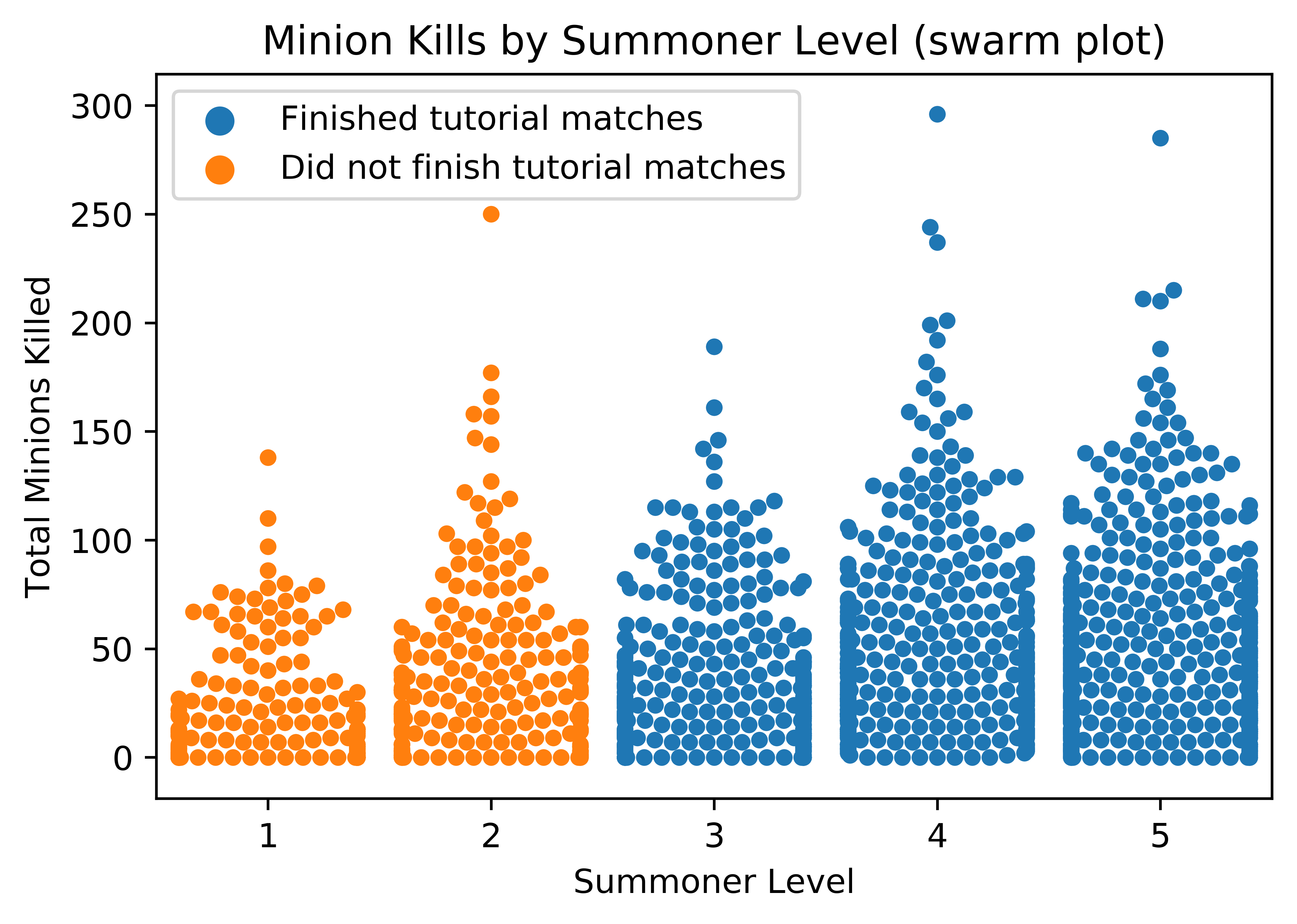
Looking at the plot we can confirm that there is a trend where the group of players that finished their tutorial matches are getting more minion kills.
Let's look at it from a different perspective:
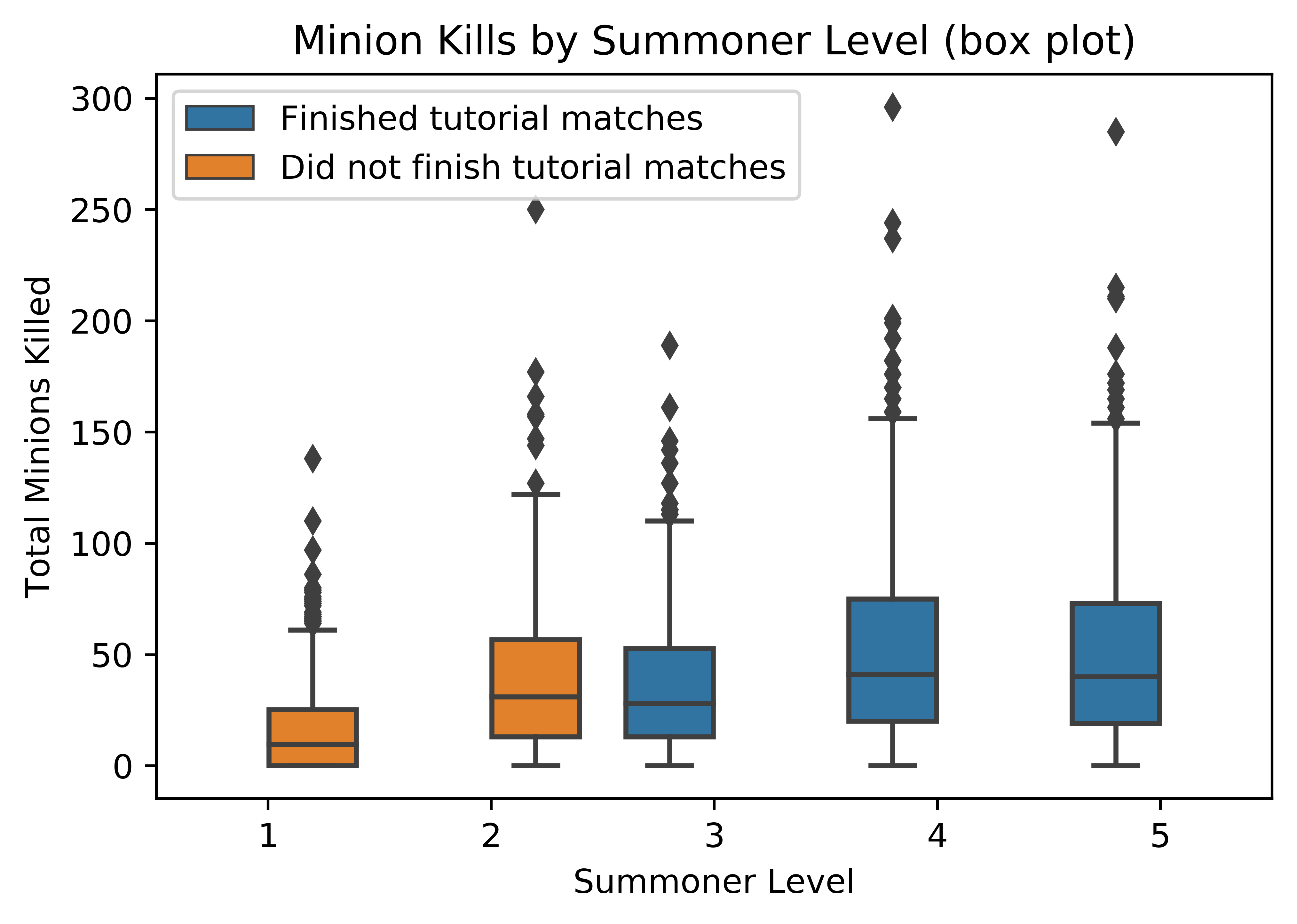
Seeing all the outliers (dots above the boxes) tells us that there are a large group of new players that are doing astoundingly well at killing minions. It is possible that those points are largely smurf accounts (new accounts made by veteran players).
Now that we have our data and have taken a look at it (however briefly), let's try our luck at predicting if a user will finish their tutorial matches or not!
Churn Prediction Modeling
To showcase the magic we're trying to capture, let's look at an example player who just finished their first match.
Here is some data from a player's first match:
| Summoner id | Win | Role | Minions Killed | Kills | Deaths | Assists | Finished Tutorial Matches? |
|---|---|---|---|---|---|---|---|
| 93729916 | Yes | Support | 27 | 6 | 2 | 6 | ???? |
Do you think they'll play another three matches? Or no? Kind of hard to say. Again, there are actually over 100 features we could examine to make a choice, but instead of pouring over all that, let's see what a logistic regression model decides instead. Because of the binary (yes/no) nature of this prediction task, a logistic regression model is a solid choice for this problem.
On this particular problem, a simple logistic regression model predicts this player will make it at least to level 3... and it's right!
Now speaking more systematically, our logistic regression model was trained on 1196 examples and then tested on 299 examples. It's accuracy on the test set was 74.25%. Not bad! This is a great starting point and shows us that this is certainly a reasonable prediction task.
Here are the accuracy results of a few more models:
| Model Type | Test set accuracy | F1-score |
|---|---|---|
| Logistic Regression | 74.25% | 0.84 |
| Decision Tree | 62.21% | 0.74 |
| Random Forests | 70.90% | 0.82 |
| Ada Boost | 70.90% | 0.81 |
Note: all models implemented with sklearn and without any hypertuning
Logistic regression is still looking like our best model. There are a few things we might want to do to improve test set accuracy. We could collect more data, we could tune the hyperparameters of our models, we could consider creating new features in our data (for example, adding in the KDA feature we created during data analysis) OR we could try different models. I chose the last option because I am interested in seeing the performance of a simple feedforward neural network model on this dataset.
Here is the basic setup of the neural network that worked best:
| Number of nodes | 213 |
|---|---|
| Number of layers | 6 |
| Learning rate | 0.001 |
| Number of epochs | 200,000 |
| Regularization | L2 |
| Optimization algorithm | Gradient Descent (tensorflow) |
It turns out that with this configuration I was able to get about 78% test set accuracy. I wasn't very happy with this outcome so I went back to my PART 1 (data collection) notebook, and gathered more data. I increased the dataset from around 1,000 rows to about .
The result of applying more data to the neural network:
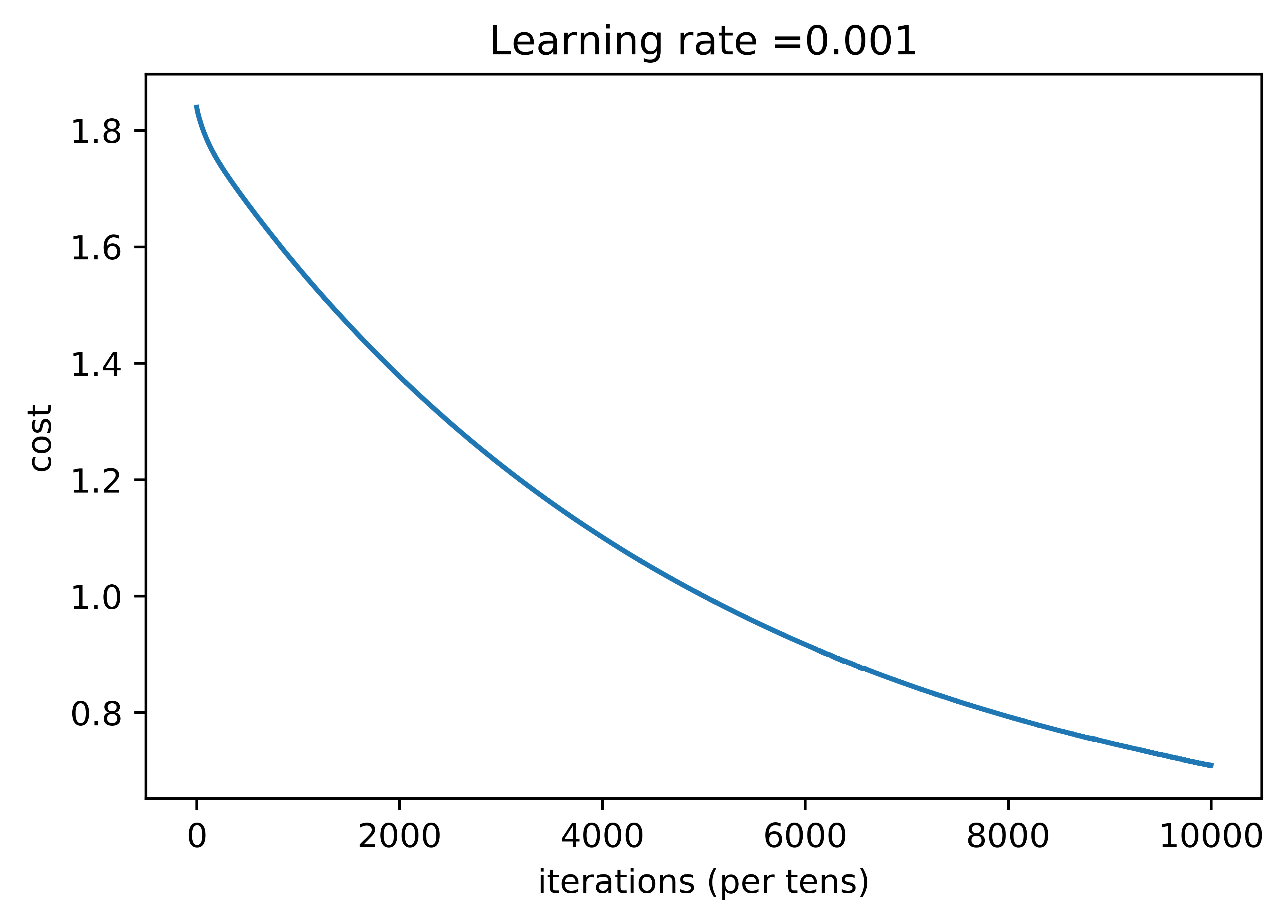
| Training accuracy | 78.2% |
|---|---|
| Test accuracy | 77.3% |
As you can see we've made a modest but solid improvement to our test set accuracy. I will continue to tune hyperparameters, and I will post an update here if I am able to improve accuracy further.
In the end, we were able to show that we can predict, with reasonably high accuracy, if a League of Legends player will get to level 3 (i.e. finish their tutorial matches) using only publically accesible game data from that player's first League of Legends match!
For detailed implementation of any part of this project, please see my Jupyter notebooks:
PART 1: Data Collection
PART 2: Data Cleaning and EDA
PART 3: Data Modeling
Thank you for your interest in this project!